
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 지니 불순도
- 데이터 분리
- 회귀 알고리즘 평가
- 가중치 업데이트
- 경사하강법
- ICDL 파이썬
- 결측값 처리
- 머신러닝 과정
- 알고리즘 기술
- 다중선형 회귀
- 이상치 처리
- 딥러닝 역사
- 분류 머신러닝 모델
- 지도학습 분류
- 퍼셉트론
- 수치 맵핑 기법
- 더미 기법
- MSEE
- 명목형
- 평가용 데이터
- LinearRegression 모델
- 지도학습
- 학습용데이터
- 데이터 전 처리
- 웹 크롤링
- 항공지연
- 불순도
- 스케이링
- 수치형 자료
- 뉴런 신경망
- Today
- Total
끄적이는 기록일지
[머신러닝] 04.지도학습-분류_(2) 의사결정나무-불순도 본문
[머신러닝] 04.지도학습-분류_(1) 분류란
[머신러닝] 03.지도학습-회귀_(1) 회귀 아이스크림 가게를 운영한다고 가정하면 지금까지 판 데이터를 가지고 우리는 예상되는 아이스크림 판매량만 주문하길 원한다. 이 때 평균 기온을 활용하
kcy51156.tistory.com
아래와 같이 들쑥날쑥한 데이터는 어떻게 나눠야할까?
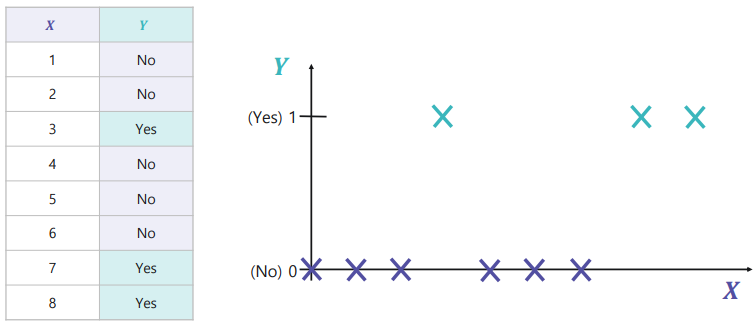
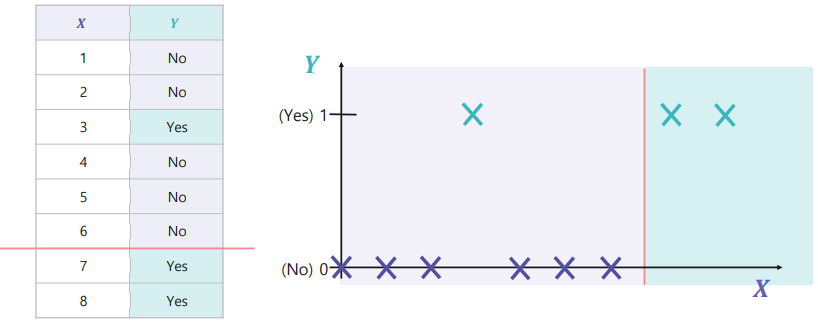
→ 이 경우에는 데이터의 불순도(Impurity)를 최소화하는 구역으로 나누어야 한다.
1. 불순도(Impurity)
- 다른 데이터가 섞여 있는 정도
- 섞여 있는 다른 데이터의 개수가 적을수록 불순도↓
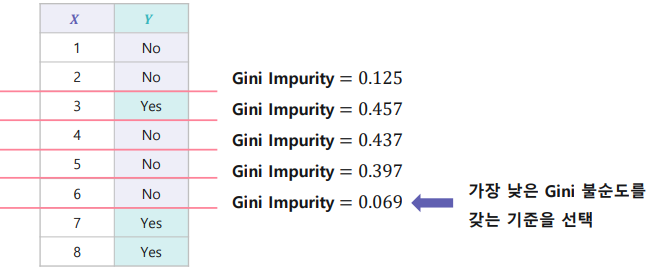
2. 불순도 측정 방법, 지니 불순도(Gini Impurity)
- 지니 계수(Gini Index) : 해당 구역 안에서 특정 클래스에 속하는 데이터의 비율을 모두 제외한 값
즉, 다양성을 계산하는 방법
- 지니 불순도(Gini Impurity)

ex)

3. 의사결정나무의 특징
- 결과가 직관적이며, 해석이 쉽다.
- 의사결정나무의 깊이(중간노드의 개수)가 깊어질수록 세분화하여 나눌 수 있지만, 너무 깊은 모델은 과적합을 야기한다.
→ 너무 깊은 모델은 지양해야 한다.
- 학습이 끝난 트리의 작업 속도가 매우 빠르다.(정해진 분리기준대로 처리하기만 하면 되기 때문)
4. 실습
아이리스 세 종류 분류
1. load_iris로 읽어 온 데이터 X에서 Y 를 바탕으로 train_test_split를 사용하여 학습용:평가용=8:2학습용 : 평가용 = 8:2학습용:평가용=8:2 비율로 분리합니다. (random_state=42는 고정합니다.)
학습하기
2. sklearn의 DecisionTreeClassifier() 모델을 DTmodel에 초기화 합니다.
3. fit을 사용하여 train_X, train_Y 데이터를 학습합니다.
예측하기
4. DTmodel을 학습하고 test_X의 예측값을 구하여 pred_X에 저장합니다.
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris #아이리스데이터셋 가져오는 함수
from sklearn.tree import DecisionTreeClassifier # 각 노드에서 불순도를 최소로 하는 의사결정나무 모델을 구현
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
# sklearn에 저장된 데이터를 불러 옵니다.
X, Y = load_iris(return_X_y = True)
# DataFrame으로 변환 (4개의 변수)
df = pd.DataFrame(X, columns=['꽃받침 길이','꽃받침 넓이', '꽃잎 길이', '꽃잎 넓이']) #feature 데이터
df['클래스'] = Y # lable데이터
X = df.drop(columns=['클래스'])
Y = df['클래스']
"""
1. 학습용 평가용 데이터로 분리합니다
"""
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state = 42)
# 원본 데이터 출력 head() : 기본 5줄까지 출력
print('원본 데이터 : \n',df.head(),'\n')
# 전 처리한 데이터 5개만 출력합니다
print('train_X : ')
print(train_X[:5],'\n')
print('train_Y : ')
print(train_Y[:5],'\n')
print('test_X : ')
print(test_X[:5],'\n')
print('test_Y : ')
print(test_Y[:5],'\n')
"""
2. DTmodel에 의사결정나무 모델을 초기화 하고
3. 학습합니다
"""
DTmodel = DecisionTreeClassifier()
# tip 깊이조절가능 : DTmodel = DecisionTreeClassifier(max_depth=2)
DTmodel.fit(train_X, train_Y)
# 학습한 결과를 출력합니다
plt.rc('font', family='NanumBarunGothic')
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(DTmodel,
feature_names=['꽃받침 길이','꽃받침 넓이', '꽃잎 길이', '꽃잎 넓이'],
class_names=['setosa', 'versicolor', 'virginica'],
filled=True)
fig.savefig("decistion_tree.png")
"""
4. test_X에 대해서 예측합니다.
"""
pred_X = DTmodel.predict(test_X)
print('test_X에 대한 예측값 : \n{}'.format(pred_X))
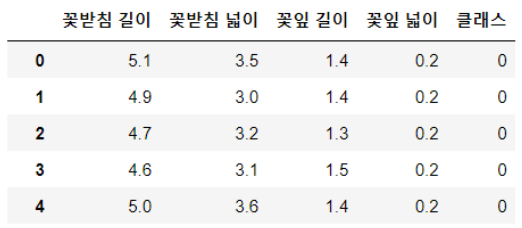
>>> 원본 데이터 :
꽃받침 길이 꽃받침 넓이 꽃잎 길이 꽃잎 넓이 클래스
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
train_X :
꽃받침 길이 꽃받침 넓이 꽃잎 길이 꽃잎 넓이
22 4.6 3.6 1.0 0.2
15 5.7 4.4 1.5 0.4
65 6.7 3.1 4.4 1.4
11 4.8 3.4 1.6 0.2
42 4.4 3.2 1.3 0.2
train_Y :
22 0
15 0
65 1
11 0
42 0
Name: 클래스, dtype: int32
test_X :
꽃받침 길이 꽃받침 넓이 꽃잎 길이 꽃잎 넓이
73 6.1 2.8 4.7 1.2
18 5.7 3.8 1.7 0.3
118 7.7 2.6 6.9 2.3
78 6.0 2.9 4.5 1.5
76 6.8 2.8 4.8 1.4
test_Y :
73 1
18 0
118 2
78 1
76 1
Name: 클래스, dtype: int32
test_X에 대한 예측값 :
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]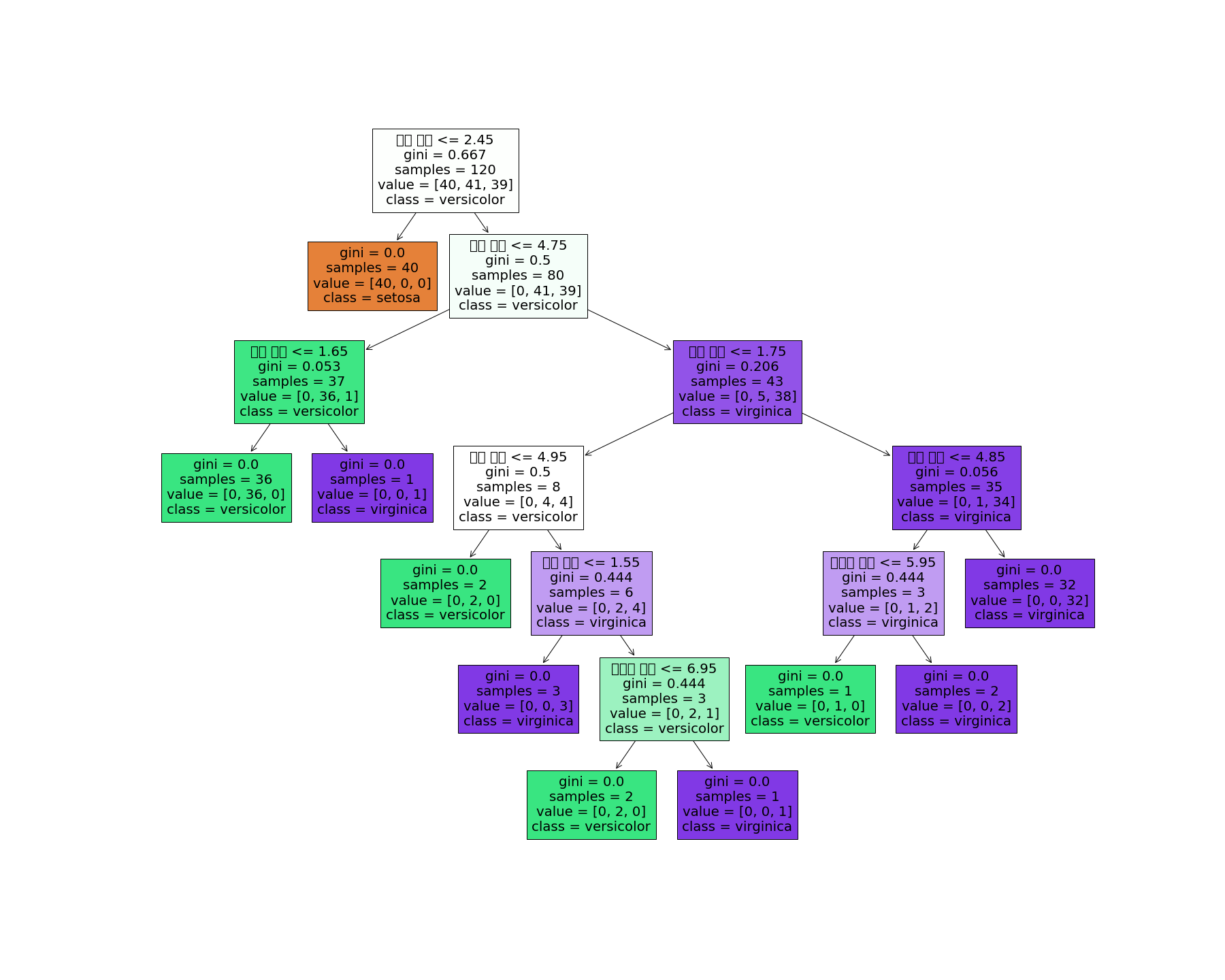
'AI실무' 카테고리의 다른 글
| [딥러닝] 01.퍼셉트론_(1)딥러닝 (0) | 2021.10.08 |
|---|---|
| [머신러닝] 04.지도학습-분류_(3) 분류 평가 지표 (0) | 2021.10.03 |
| [머신러닝] 04.지도학습-분류_(1) 분류란 (1) | 2021.10.03 |
| [머신러닝] 03.지도학습-회귀_(3) 회귀 성능 지표 (0) | 2021.09.25 |
| [머신러닝] 03.지도학습-회귀_(3) 다중 선형 회귀 (0) | 2021.09.25 |



