
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 회귀 알고리즘 평가
- 가중치 업데이트
- 딥러닝 역사
- 명목형
- 경사하강법
- 머신러닝 과정
- 항공지연
- 더미 기법
- 수치형 자료
- LinearRegression 모델
- 수치 맵핑 기법
- 결측값 처리
- 다중선형 회귀
- 웹 크롤링
- 이상치 처리
- 스케이링
- ICDL 파이썬
- 알고리즘 기술
- 평가용 데이터
- 불순도
- 데이터 전 처리
- 지니 불순도
- MSEE
- 분류 머신러닝 모델
- 지도학습
- 퍼셉트론
- 학습용데이터
- 지도학습 분류
- 뉴런 신경망
- 데이터 분리
- Today
- Total
끄적이는 기록일지
[머신러닝] 03.지도학습-회귀_(3) 다중 선형 회귀 본문
[머신러닝] 03.지도학습-회귀_(2) 단순 선형 회귀
[머신러닝] 03.지도학습-회귀_(1) 회귀 아이스크림 가게를 운영한다고 가정하면 지금까지 판 데이터를 가지고 우리는 예상되는 아이스크림 판매량만 주문하길 원한다. 이 때 평균 기온을 활용하
kcy51156.tistory.com
지난 시간에 이어 아이스크림 판매량을 예로 들어 설명하겠습니다.
평균 기온에 따라 아이스크림 판매량을 알아보았는데
이번에는 입력값 X에 강수량을 추가한다면 어떻게 될까요?

평균 기온(X1)과 평균 강수량(X2)에 따른 아아스크림 판매량(Y)을 예측하는 것이기 때문에
≫ 여러 개의 입력값(X)으로 결괏값(Y)을 예측하고자 하는 경우는 다중 선형 회귀를 사용한다.
1. 다중 선형 회귀(Multiple Linear Regression)
1) 입력값 𝑋가 여러 개(2개 이상)인 경우 활용할 수 있는 회귀 알고리즘
2) 각 개별 𝑿𝒊에 해당하는 최적의 𝜷𝒊를 찾아야 함.

평균 기온과 평균 강수량에 따른 아이스크림 판매량을 예측하고자 한다면

2. 다중 선형 회귀 모델의 Loss 함수
1) 단순 선형 회귀와 마찬가지로 Loss 함수는 입력값과 실제값 차이의 제곱의 합으로 정의.
2) 마찬가지로 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴값을 조절하여 Loss 함수의 크기를 작게 합니다.
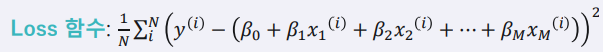
3) 평균 기온과 평균 강수량에 따른 아이스크림 판매량을 예측 예시

3. 다중 선형 회귀 모델의 경사 하강법
- 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴 값을 Loss 함수 값이 작아지게 계속 업데이트 하는 방법
1) 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴 값을 랜덤하게 초기화
2) 현재 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴값으로 Loss 값 계산
3) 현재 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴 값을 어떻게 변화해야 Loss 값을 줄일 수 있는지 알 수 있는 Gradient 값 계산
4) Gradient 값을 활용하여 𝜷𝟎,𝜷𝟏,𝜷𝟐, … ,𝜷𝑴 값 업데이트
5) Loss 값의 차이가 거의 없어질 때까지 2~4번 과정을 반복
(Loss 값과 차이가 줄어들면 Gradient 값도 작아 짐)
- 다중 선형 회귀 모델의 경사 하강법 결과 예시
평균 기온과 평균 강수량에 따른 아이스크림 판매량을 예측 예시

4. 다중 선형 회귀 특징
1) 여러 개의 입력값과 결괏값 간의 관계 확인 가능

2) 어떤 입력값이 결괏값에 어떠한 영향을 미치는지 알 수 있음
3) 여러 개의 입력값 사이 간의 상관 관계*가 높을 경우 결과에 대한 신뢰성을 잃을 가능성이 있음
상관 관계* : 두 가지 것의 한쪽이 변화하면 다른 한쪽도 따라서 변화하는 관계
5. 실습
* 다중 회귀 분석 : 데이터의 여러 변수(features) X를 이용해 결과 Y를 예측하는 모델
마케터들에게는 광고 비용에 따른 수익률을 머신러닝을 통해서 예측할 수 있다면 어떤 광고 플랫폼이 중요한 요소인지 판별할 수 있을 것입니다.
아래와 같이 FB, TV, Newspaper 광고에 대한 비용 대비 Sales 데이터가 주어졌을 때, 이를 다중 회귀 분석으로 분석해봅시다.
새로운 광고 비용에 따른 Sales 값을 예측해봅시다.
1. DataFrame으로 읽어 온 df에서 Sales 변수는 label 데이터로 Y에 저장하고 나머진 X에 저장합니다.
2. train_test_split를 사용하여 X, Y를 학습용:평가용=8:2 비율로 분리합니다.
(random_state = 42는 고정합니다.)
3. 다중 선형 회귀 모델 LinearRegression을 불러와 lrmodel에 초기화하고 fit을 사용하여 train_X, train_Y데이터를 학습합니다.
4. 학습된 모델 lrmodel에서 beta_0, beta_1, beta_2, beta_3에 해당하는 파라미터를 불러와 저장합니다.
* 다중 선형 회귀 수식 Sales=β0+β1X1+β2X2+β3X3
(X1 :페이스북, X2 :TV, X3 :신문광고)
5. lrmodel을 학습하고 test_X의 예측값을 구하여 pred_X에 저장합니다.
6. lrmodel을 학습하고 주어진 데이터 df1의 예측값을 구하여 pred_df1에 저장합니다
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
#데이터 형태로 받아옴
df = pd.read_csv("Advertising.csv")
print('원본 데이터 샘플 :')
print(df.head(),'\n')
# 입력 변수로 사용하지 않는 Unnamed: 0 변수 데이터를 삭제합니다
df = df.drop(columns=['Unnamed: 0'])
"""
1. Sales 변수는 label 데이터로 Y에 저장하고 나머진 X에 저장합니다.
"""
X = df.drop(columns=['Sales']) # feature데이터 : Sales데이터 제외한 부분
Y = df['Sales'] # lable데이터 : Sales만 뽑아 시리즈로 나타내면
"""
2. 학습용 평가용 데이터로 분리합니다.
"""
train_X, test_X, train_Y, test_Y = train_test_split( X, Y, test_size=0.2, random_state=42)
# 전 처리한 데이터를 출력합니다
print('1. train_X : ')
print(train_X.head(),'\n')
print('train_Y : ')
print(train_Y.head(),'\n')
print('2. test_X : ')
print(test_X.head(),'\n')
print('test_Y : ')
print(test_Y.head(),'\n')
"""
3. 다중 선형 회귀 모델을 초기화 하고 학습합니다
"""
lrmodel = LinearRegression()
lrmodel.fit(train_X, train_Y)
"""
4. 학습된 파라미터 값을 불러옵니다
lrmodel = LinearRegression()
lrmodel.intercept_
lrmodel.coef_[i] #i+1 번째 변수에 곱해지는 파라미터 값
"""
beta_0 = lrmodel.intercept_ # y절편 (기본 판매량) β0에 해당하는 값
beta_1 = lrmodel.coef_[0] # 1번째 변수에 대한 계수 (페이스북)
beta_2 = lrmodel.coef_[1] # 2번째 변수에 대한 계수 (TV)
beta_3 = lrmodel.coef_[2] # 3번째 변수에 대한 계수 (신문)
print("4. beta_0: %f" % beta_0)
print("beta_1: %f" % beta_1)
print("beta_2: %f" % beta_2)
print("beta_3: %f\n\n" % beta_3)
"""
5. test_X에 대해서 예측합니다.
"""
pred_X = lrmodel.predict(test_X)
print('5. test_X에 대한 예측값 : \n{}\n'.format(pred_X))
# 새로운 데이터 df1을 정의합니다
df1 = pd.DataFrame(np.array([[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1]]), columns=['FB', 'TV', 'Newspaper'])
print('df1 : ')
print(df1)
"""
6. df1에 대해서 예측합니다.
"""
pred_df1 = lrmodel.predict(df1)
print('6. df1에 대한 예측값 : \n{}'.format(pred_df1))
>>> 원본 데이터 샘플 :
Unnamed: 0 FB TV Newspaper Sales
0 1 230.1 37.8 69.2 22.1
1 2 44.5 39.3 45.1 10.4
2 3 17.2 45.9 69.3 9.3
3 4 151.5 41.3 58.5 18.5
4 5 180.8 10.8 58.4 12.9
1. train_X :
FB TV Newspaper
79 116.0 7.7 23.1
197 177.0 9.3 6.4
38 43.1 26.7 35.1
24 62.3 12.6 18.3
122 224.0 2.4 15.6
train_Y :
79 11.0
197 12.8
38 10.1
24 9.7
122 11.6
Name: Sales, dtype: float64
2. test_X :
FB TV Newspaper
95 163.3 31.6 52.9
15 195.4 47.7 52.9
30 292.9 28.3 43.2
158 11.7 36.9 45.2
128 220.3 49.0 3.2
test_Y :
95 16.9
15 22.4
30 21.4
158 7.3
128 24.7
Name: Sales, dtype: float64
4. beta_0: 2.979067
beta_1: 0.044730
beta_2: 0.189195
beta_3: 0.002761
5. test_X에 대한 예측값 :
[16.4080242 20.88988209 21.55384318 10.60850256 22.11237326 13.10559172
21.05719192 7.46101034 13.60634581 15.15506967 9.04831992 6.65328312
14.34554487 8.90349333 9.68959028 12.16494386 8.73628397 16.26507258
10.27759582 18.83109103 19.56036653 13.25103464 12.33620695 21.30695132
7.82740305 5.80957448 20.75753231 11.98138077 9.18349576 8.5066991
12.46646769 10.00337695 21.3876709 12.24966368 18.26661538 20.13766267
14.05514005 20.85411186 11.0174441 4.56899622]
df1 :
FB TV Newspaper
0 0 0 0
1 1 0 0
2 0 1 0
3 0 0 1
4 1 1 1
6. df1에 대한 예측값 :
[2.97906734 3.02379686 3.16826239 2.98182845 3.21575302]
'AI실무' 카테고리의 다른 글
| [머신러닝] 04.지도학습-분류_(1) 분류란 (1) | 2021.10.03 |
|---|---|
| [머신러닝] 03.지도학습-회귀_(3) 회귀 성능 지표 (0) | 2021.09.25 |
| [머신러닝] 03.지도학습-회귀_(2) 단순 선형 회귀 (0) | 2021.09.25 |
| [머신러닝] 03.지도학습-회귀_(1) 회귀 (0) | 2021.09.25 |
| [머신러닝] 02.데이터 전처리_(4) 데이터 정제 및 분리 (1) | 2021.09.15 |



